The LS Insight setup process creates the LS Insight - Azure Data Factory (ADF). The ADF contains everything needed to populate the star schema dimensions and facts in the LS Insight - Data Warehouse. This topic describes all the different factory resources and how they are used.
Note: This is a detailed description of the ADF components to give you a better understanding of what happens where. Everything about how to use the ADF when setting up LS Insight is explained in the onboarding process.
Overview
The components are:
- Integration runtime gateway
- Linked services
- Pipelines
To view these components in the Azure portal you need to open the LS Insight ADF from the resource list and then select Author & Monitor from the overview page.
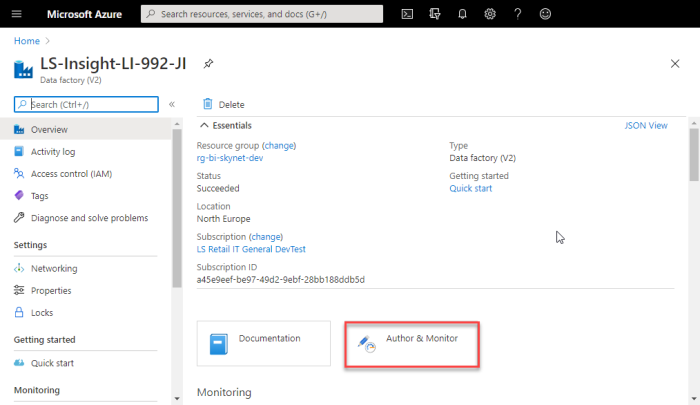
When you open the Author & Monitor view, you will see a new tab in your browser and get access to the data factory menu that will be referenced many times in this ADF description. The menu consists of icons and labels that lead to the different sections.
Data Factory
This is just a generic section where you can access videos and knowledge about how to get started with ADF. Since the LS Insight ADF is created by the deployement script, you can just use this information if you want to explore the options of ADFs further.
Author
The Author section is the heart of the ADF. In this section you have access to the pipelines that are an essential part of the LS Insight ETL.
Pipelines
The LS Insight pipelines are arranged in a folder structure by where in the process they are used. Some pipelines query the LS Central source database, while others move data between tables in the Data Warehouse by running stored procedures from the DW database. Other pipelines are created to control the order the pipelines are run in. Their only purpose is to execute other pipelines.
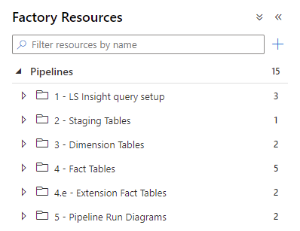
This folder contains six pipelines.
Add or Delete App Affix
When this pipeline is triggered, you can add or delete an App Affix from the LSInsight$PublisherAffixReg table. The AppID, AppName, and Publisher parameters are required but you only have to provide either a Prefix or Suffix. If you set the deleteApp parameter to TRUE, you only have to provide the AppID to delete the App registration from the table. For LS Central versions that have extension GUIDs you must register all extensions you want to use in LS Insight in this table. If a registration does not exist, no data will be loaded from the extension table to LS Insight.
Add or Delete Companies
When this pipeline is triggered, you can add a company name to be added to or deleted from the Companies table. The deleteCompanies parameter decides whether the company is added or deleted. You can add more than one company at a time; you just need to separate the names by a comma in the LSInsight$Companies field.
Example:
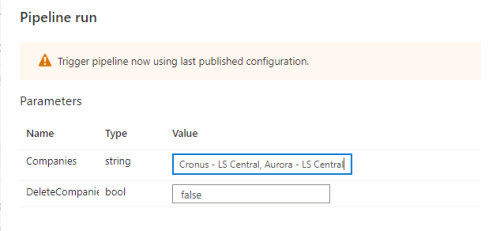
This pipeline is not used, unless you want to trigger it manually to add a new company to your current LS Insight instance.
Add or Delete ShortTableNameMap
When the extension table affixes were introduced in LS Central 17.5, some of the LS Central extension table names had to be shortened. Instead of changing all our stored procedures and having different procedures between LS Central versions, we decided to create a map from the old LS Central table names to the new ones. This means that we can change the new short names back to the older names to use in our data warehouse staging tables.
This pipeline allows you to add or delete a new table name map to the LSInsight$ShortTableNameMap table. You are required to provide both the Original table name and the new shorter table name to create the mapping. To delete you can provide either one to delete the row.
Add or Delete Source Tables
When this pipeline is triggered, you can add an LS Central source table name to be added to or deleted from the LSInsight$SourceTabels table. The deleteSourceTable parameter decides whether the Source table name is added or deleted. You can add more than one source table at a time, you just need to separate them by a comma.
PopulateQueryBase
This pipeline has two parts that are by default run one after the other, but can be run separately, if needed.
The first part is Get Metadata. Here a query is sent to theLS Central source database to collect information about all tables and fields.
This meta data is then used in the second stage Populate Query Base to create the staging queries for all tables listed in the LSInsight$SourceTable table and adding them to the LSInsight$QUERYBASE table.
After the pipeline has run, the LSInsight$QUERYBASE has been populated with creation scripts for the staging tables, where the Business Central (BC) base table has been combined with all extension tables with the same name, into one LS Insight staging table.
The query base also contains select queries used by the All Staging Tables pipeline to populate the staging tables.
This pipeline is run once during the onboarding process and does not need to be run again, unless LS Central is updated with new extensions that should be added to LS Insight, or if you want to add a new staging table to extend LS Insight beyond the standard version provided by LS Retail.
The Extending LS Insight section of the LS Insight online help explains in further detail how to extend your LS Insight instance, since the extension steps differ depending on which LS Central platform you are running on.
Reset LS Insight DW
This pipeline runs a stored procedure on the database that deletes all retail data from the database, without deleting any of the necessary meta data that is included when the database is created from the template. This pipeline should always be run as a part of the Factory reset pipeline.
All Staging Tables
This pipeline is run as part of the Scheduled Run pipeline that should be scheduled to run every day.
It starts by getting the first company from the Companies table, and then looping through all tables in SourceTables, creating the staging tables and populating them with data from the LS Central source.
The same thing is then done for all additional companies, LS Central is queried and the staging tables are populated with information from each company.
The RowID of the last staging table is then stored in the LS Insight Audit table to ensure incremental load when applicable.
This pipeline has a few parameters that can be used for testing. The default values are shown in the image:
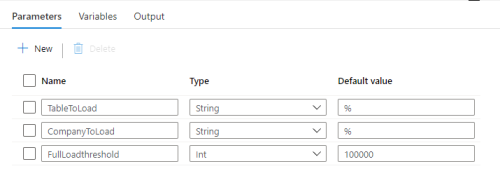
-
TableToLoad - Here you can add the name of one or more tables that should be loaded. Here you do not provide the table names separated by comma, but instead supply the string used for a "like" comparison on the table name. So if you were to add something like '%Item%' to the parameter field, the pipeline would run for all tables that contained the word 'Item'.
-
CompanyToLoad - This parameters works exactly the same as the TableToLoad, except that it filters companies, not tables.
-
FullLoadthreshold - The full load threshold determines how many rows a table can have before doing an incremental load instead of a full load of the table from source to staging. This is because the incremental load always has some cost, so it is not worth doing an incremental load for tables with relatively few rows. You only want to do incremental load on tables with many rows and where many rows are being added each day, like the transaction and entry tables.
The Dimension folder contains two pipelines. These pipeline are run as part of the Scheduled Run pipeline that should be scheduled to run every day.
Execute Dimension Stored Procedures
This pipeline starts by populating the dCompany dimension table. It then runs through all the stored procedures in the LS Insight DW database that start with dim. Those stored procedures (SP) usually combine several staging tables to create the dimension table and add and update data as needed.
Dimensions that are part of LS Central extensions, such as LS Central for Hotels, are also run by this pipeline. So if the tables exist in LS Central, the staging tables are created by the previous step and the dimensions are loaded by this pipeline along with the other dimensions the extension SPs are prefixed with dimext.
You can find all the stored procedures in the LS Insight database under Programmability - Stored Procedures.
The pipeline runs the dimension SPs in parallel as much as possible.
PL-SP-odMemberAttributes
This pipeline runs the stored procedure for the odMemberAttributes dimension. This is an out trigger dimensions and must be run after other dimension tables have been updated, because it combines data from staging tables and the dMember dimension.
There are five fact table pipelines that run five fact table stored procedures. They are run one by one, because there are so few and we want to control the order they are run in. These pipelines are run as part of the Scheduled Run pipeline that should be scheduled to run every day.
PL-SP-factDiscount
PL-SP-factInventory
PL-SP-FactSalesPosted
PL-SP-postfactUpdateAdjustedCost
PL-SP-prefactItemCostAdjustments
PL-SP-factACIAlerts
PL-SP-factACIDiscounts
PL-SP-factPurchaseCreditMemo
PL-SP-factPurchaseInvoice
PL-SP-factPurchaseOrders
PL-SP-factPurchaseReceipts
Currently, there are only two extension fact table pipelines and both of them are for the LS Central Hotels extension. This is currently the only available extension for LS Insight, but more are coming.
If the Hotel source tables are enabled in the LSInsight$Sourcetables table and the extension and tables exist in the LS Central database, the data will be automatically loaded into the LS Insight data warehouse so no special setup is needed. All the tables and stored procedures for Hotels already exist in the Data Warehouse template.
PL-SP-factHotelDetailedRevenue
PL-SP-factHotelStatistic
This folder contains the pipeline that should be run to run all the other pipelines listed above. Most of these pipelines should never be run individually, but we categorized them into folders and explain them here, so you are familiar with the processes and able to extend, if needed.
For information about how to extend the LS Insight data warehouse and what pipelines to run after you extend, see the Extending LS Insight section of the online help.
Factory reset
This pipeline first executes the Reset LS Insight DW pipeline to clean all retail data from the data warehouse. Then it runs the Initial load pipeline to fully populate LS Insight with data from LS Central.
If you are experiencing some data issues in LS Insight, that might be caused by importing data to LS Central from an external system, or if you have at some point changed the LS Central source for LS Insight, it is good to run Factory reset to make sure that the issues you are experiencing are not caused by data mismatch between LS Central and LS Insight.
Initial load
This pipeline executes the Populate Query Base and Scheduled Run pipelines and it should only be manually triggered during the initial setup of LS Insight.
Scheduled Run
Like the name suggests this is the pipeline that should be scheduled to run once every 24 hours.
This pipeline executes all the other pipelines needed to load the LS Insight Data Warehouse.
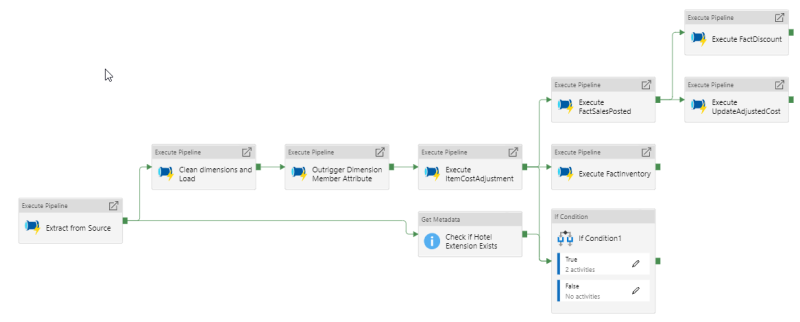
Extract from Source executes All staging Tables pipeline.
Clean dimensions and Load executes Execute Dimension Stored Procedures pipeline.
Outrigger Dimension Member Attribute executes PL-SP-odMemberAttributes pipeline.
Execute Item Cost Adjustment executes PL-SP-prefactItemCostAdjustment pipeline.
Parallel to this we Check if the Hotel Extension Exists, and if that check is true the Hotel fact tables stored procedures can be run parallel to the other fact table procedures. The If Condition 1 runs the two Hotel pipelines PL-SP-factHotelDetailedRevenue and PL-SP-factHotelStatistic.
Execute FactSalesPosted executes PL-SP-FactSalesPosted.
Execute FactInventoryexecutes PL-SP-factInventory.
Execute FactDiscount executes PL-SP-factDiscount and must be executed after FactSalesPosted because it uses information from FactSalesPosted.
Execute UpdateAdjustedCost executes PL-SP-postfactUpdateAdjustedCost and must be executed after FactSalesPosted because it updates that fact table with cost changes.
Datasets
There are three data sets in the LS Insight Datasets folder and they are used in different lookup activities in the pipelines.
LSCentralColumnMetadata
LSInsightDW
SourceDataset
Monitor
A special page is dedicated to Monitoring pipelines while they run. This goes both for scheduled pipelines and monitoring of manually triggered pipelines and pipeline chains.
Manage
The Manage section of the Azure Data Factory contains the Integration runtimes gateway and the Linked services. Both play a part in the connection from Azure to the LS Central source database and to the LS Insight DW.
Integration runtime gateway
The manual setup of the LSInsight-IntegrationRuntime gateway is explained in the LS Insight onboarding process. It is only needed when LS Central is on-premises, otherwise the AutoResolvedIntegrationRuntime is used.
Tip: Microsoft has some extensive documentation about the integration runtime.
Linked services
The LS Insight onboarding process creates the ADF with two linked services.
LS Central source
This linked service stores the connection to the LS Central source database and utilizes the LSInsight-IntegrationRuntime for that connection.
LSInsightDW
This linked service stores the connection to the LS Insight DW database.
If the LS Insight database is located in Azure, it uses the AutoResolvedIntegrationRuntime to connect to the Azure SQL database, but if LS Insight is located on-premise within the same domain as the LS Central database, it can utilize the LSInsight-IntegrationRuntime that was created during the LS Insight setup.